十八款Hadoop工具,帮你高效驯服大数据
在当今数据驱动的时代,Hadoop作为处理海量数据的核心框架,其强大的分布式计算和存储能力已成为企业驾驭大数据的基石。一个完整的“大数据生态系统”远不止于Hadoop本身,一系列围绕其构建的互补工具和服务,共同构成了强大、灵活且高效的数据处理与存储支持体系。以下精选的十八款工具,将助您全方位地驯服大数据。
一、 数据存储与管理层
- HDFS (Hadoop Distributed File System): 基石中的基石,提供高容错、高吞吐量的数据存储服务,是Hadoop生态的存储核心。
- HBase: 构建于HDFS之上的分布式、面向列的NoSQL数据库,适合实时读写和随机访问超大规模稀疏数据集。
- Apache Kudu: 填补HDFS批量存储与HBase低延迟存储之间的空白,支持快速分析的同时也支持实时更新,适合时序数据等场景。
二、 资源调度与协调层
- YARN (Yet Another Resource Negotiator): Hadoop 2.0引入的核心组件,负责集群资源管理和作业调度,让多种计算框架(如MapReduce, Spark)可以共享集群资源。
- Apache ZooKeeper: 分布式应用的“协调员”,提供分布式锁、配置维护、命名服务等,是HBase、Kafka等众多分布式系统稳定运行的关键依赖。
三、 数据处理与计算引擎
- MapReduce: 经典的批处理编程模型,适合处理超大规模数据集的离线计算任务,稳定性极高。
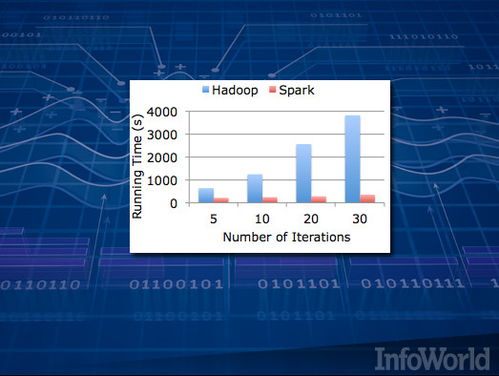
- Apache Spark: 基于内存计算的统一分析引擎,在批处理、流处理、交互式查询和机器学习方面表现卓越,速度远超MapReduce。
- Apache Flink: 真正的流处理优先计算框架,提供高吞吐、低延迟、精确一次(exactly-once)的状态计算,在实时处理领域优势明显。
- Apache Tez: 旨在提升Hive、Pig等批处理作业执行效率的通用计算框架,通过优化任务执行计划来减少延迟。
四、 数据查询与分析层
- Apache Hive: 基于Hadoop的数据仓库工具,提供类SQL的查询语言(HiveQL),将SQL语句转换为MapReduce/Tez/Spark任务,降低了大数据查询门槛。
- Apache Impala: 专为HDFS和HBase设计的MPP(大规模并行处理)SQL查询引擎,无需MapReduce,可直接提供低延迟的交互式SQL查询。
- Presto: Facebook开源的分布式SQL查询引擎,支持跨多种数据源(如HDFS, Hive, Kafka, RDBMS)进行快速交互式分析。
- Apache Pig: 提供高级脚本语言Pig Latin,简化了复杂MapReduce程序的开发,更适合数据流水线(ETL)任务。
五、 数据采集与集成层
- Apache Sqoop: 用于在Hadoop与结构化数据存储(如关系型数据库)之间高效传输批量数据的工具。
- Apache Flume: 一个高可用的、高可靠的分布式海量日志采集、聚合和传输系统,非常适合将流式日志数据摄入HDFS。
- Apache Kafka: 分布式流数据平台,作为高吞吐量的消息队列,是构建实时数据管道和流应用的核心,常作为流处理引擎(如Spark Streaming, Flink)的数据源。
六、 工作流调度与元数据管理
- Apache Oozie: Hadoop的工作流调度系统,用于管理和协调复杂的多步骤数据处理作业(如包含Hive、Pig、Sqoop的任务序列)。
- Apache Atlas: 为Hadoop生态系统提供元数据管理与治理框架,支持数据分类、血缘追踪、合规性审计,是数据治理的关键工具。
###
这十八款工具各司其职,又紧密协作,共同构建了一个从数据摄入、存储、计算、分析到治理的完整闭环。选择与组合这些工具时,需根据具体的业务场景(如批处理优先还是实时处理优先)、技术栈熟悉度及团队运维能力进行权衡。熟练掌握这个强大的工具箱,您将能游刃有余地应对大数据带来的挑战,真正释放数据的巨大价值。
如若转载,请注明出处:http://www.xnjindouyun.com/product/49.html
更新时间:2026-06-19 20:52:56