AI原生存储 赋能大模型的数据基石,重塑数据处理与存储支持服务

随着人工智能,特别是大语言模型、多模态模型和生成式AI的飞速发展,数据已成为驱动这场智能革命的核心燃料。大模型训练与推理对数据存储提出了前所未有的挑战:海量非结构化数据(文本、图像、音频、视频)、极高的读写吞吐量需求、数据预处理与标注的复杂性,以及对数据一致性、安全性和全生命周期管理的严苛要求。在此背景下,“AI原生存储”应运而生,它并非简单的硬件堆叠或存储扩容,而是一种面向AI工作负载,深度融合数据处理与存储支持服务的全新架构范式。
一、AI原生存储的核心内涵:为智能而生
AI原生存储的核心在于其“原生性”。它从设计之初便深度理解AI数据流水线的各个环节——从数据采集、清洗、标注、预处理,到模型训练、验证、部署和推理。它旨在打破传统存储系统与计算系统之间的壁垒,实现数据与算力的高效协同。其关键特征包括:
- 数据与算力紧耦合: 支持GPU/NPU直接访问存储数据(如通过GPUDirect Storage技术),大幅减少数据在CPU内存中的拷贝和搬运,将宝贵的计算资源从I/O瓶颈中解放出来,显著提升训练效率。
- 极致性能与扩展性: 针对AI负载中常见的“读多写少”、小文件海量、大文件顺序读写等混合模式进行深度优化。采用全闪存架构、分布式文件系统或对象存储,提供线性扩展的带宽和IOPS,轻松应对从PB到EB级的数据规模增长。
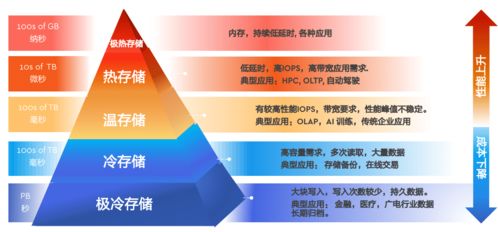
- 智能数据管理: 内嵌数据感知与管理能力。例如,自动识别“热数据”(频繁访问的训练集)与“冷数据”(归档的旧版本数据),实施智能分层存储,优化成本与性能的平衡。支持数据版本控制、快照和克隆,便于模型迭代与回滚。
- 集成化数据处理支持: 将部分数据预处理功能(如解码、格式转换、数据增强)下沉到存储层或近存储层执行,实现“存算一体”或“近存计算”,进一步减少数据传输开销,加速整体流水线。
二、提升大模型数据存储能力的关键路径
AI原生存储如何具体提升大模型的能力?主要体现在以下几个层面:
- 加速训练周期: 通过提供超高吞吐量和低延迟的数据供给,确保成千上万的GPU计算单元能够持续“饱腹”工作,避免因数据I/O等待造成的算力闲置,从而将数月甚至数年的训练时间大幅缩短。
- 支撑超大规模数据集: 大模型的性能提升严重依赖于数据规模与质量。AI原生存储的横向扩展能力,能够无缝容纳互联网级的海量、多模态训练数据,为模型“投喂”更丰富、更优质的养分。
- 保障数据流水线敏捷性: 支持快速的数据湖/数据仓库构建,方便数据科学家和工程师进行数据探索、实验和管理。高效的数据版本管理和共享机制,使得团队协作与模型复现更加顺畅。
- 增强数据安全与合规: 提供端到端的数据加密、访问控制、审计日志以及数据脱敏功能,满足企业在使用敏感数据训练模型时的安全与隐私合规要求。
三、一体化数据处理与存储支持服务:从基础设施到价值实现
AI原生存储的价值不止于“存储”,更在于提供一体化的“数据处理与存储支持服务”。这构成了一个完整的服务栈:
- 基础设施即服务: 提供高性能、高可靠、弹性伸缩的存储资源池,无论是本地部署、公有云还是混合云环境,都能以服务的形式灵活交付。
- 数据流水线即服务: 集成数据接入、转换、标注、质量监控等工具链,提供开箱即用的数据处理工作流模板,降低AI团队的数据工程门槛。
- 性能优化与调优服务: 基于对AI工作负载的深度洞察,提供专业的存储配置、数据布局和访问模式优化建议,确保系统始终处于最佳运行状态。
- 运维管理与智能运维: 提供统一的监控、告警、容量规划和预测性维护能力。利用AI技术来管理AI存储,实现故障自愈和性能自优化。
四、展望未来:存储与智能的深度融合
AI原生存储将朝着更深度智能化的方向发展。存储系统不仅能被动响应请求,更能主动理解AI应用的数据语义和访问意图,进行预测性数据预取和布局。以计算存储(Computational Storage)为代表的存算融合技术将进一步发展,将部分模型推理或特定算子直接卸载到存储设备中执行,开创“数据在哪里,计算就在哪里”的新模式。
AI原生存储是释放大模型潜力的关键基础设施。它通过重新定义存储架构,提供深度融合的数据处理与存储支持服务,正成为企业构建AI核心竞争力的数据基石,助力其在智能化浪潮中稳健前行。
如若转载,请注明出处:http://www.xnjindouyun.com/product/47.html
更新时间:2026-06-19 14:40:18