AI数据存储与流动的清晰图解 数据处理与存储支持服务详解
在人工智能(AI)飞速发展的今天,数据作为其核心驱动力,其处理与存储的流程直接影响着AI系统的效率与智能水平。理解数据从产生到最终被模型利用的全过程,是优化AI应用的关键。本文将提供一个清晰的图解视角,系统阐述AI系统中的数据流动路径,并深入解析支撑这一流程的底层数据处理与存储支持服务。
一、 AI数据流动全流程图解
一个典型的AI数据生命周期可概括为以下核心环节,它们构成了一个持续迭代的闭环:
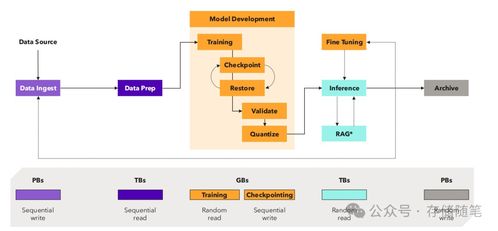
- 数据采集与注入:数据从各种源头(如物联网设备、业务数据库、日志文件、公开数据集等)被收集。通过消息队列(如Kafka)、数据同步工具或API接口,原始数据被实时或批量地“注入”到数据系统中。这是数据流的起点。
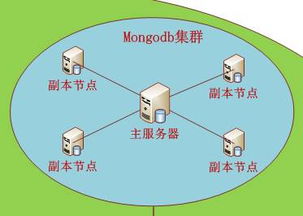
- 数据存储与湖仓:采集到的原始数据首先被存入数据湖(如基于HDFS、S3的对象存储),这是一个存储所有原始格式数据的巨大仓库。经过部分处理的数据可进入数据仓库(如Snowflake、BigQuery),其结构更优化,便于商业智能分析。而专为AI设计的数据平台则常采用 “湖仓一体” 架构,兼顾灵活性与高性能。
- 数据处理与加工:这是将原始数据转化为AI可用“燃料”的核心阶段。它包括:
- 数据清洗:去除错误、重复、不完整的脏数据。
- 数据标注:为监督学习任务,由人工或辅助工具为数据打上标签。
- 特征工程:通过转换、组合、统计等方法,从原始数据中提取出对模型预测更有价值的特征。此过程通常在数据处理框架(如Spark、Flink)中完成。
- 模型训练与迭代:处理好的特征数据被送入模型训练平台(如TensorFlow, PyTorch集群)。训练过程需要高速、低延迟地读取海量数据,并对中间模型参数(检查点)进行频繁保存,这要求底层存储具备极高的吞吐能力和并行访问性能。
- 模型部署与推理:训练好的模型被部署为在线服务。在推理阶段,新的实时数据流入,模型进行计算并返回预测结果。这个过程要求极低的推理延迟,通常需要将模型和所需特征数据加载到高速缓存(如Redis)或内存数据库中。
- 反馈与闭环:推理结果在实际应用中产生的效果数据(如用户点击、行为反馈)又被作为新的数据源采集回来,用于评估模型效果、发现数据漂移,并触发新一轮的数据标注和模型再训练,从而形成持续优化的闭环。
二、 关键的数据处理与存储支持服务
为了保障上述数据流高效、稳定、安全地运转,一系列支持服务至关重要:
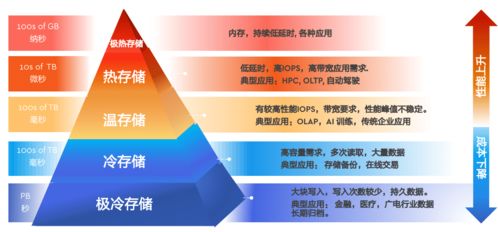
- 高性能分布式存储:
- 对象存储:如AWS S3、阿里云OSS,提供海量、廉价、持久的原始数据存储,是数据湖的基石。
- 文件存储:如HDFS、GPFS,为大规模批处理作业提供高吞吐量的数据访问。
- 块存储与云盘:为数据库、高性能计算节点提供低延迟、高IOPS的存储支持。
- 弹性计算与数据处理框架:
- 基于容器的服务(如Kubernetes)提供弹性的计算资源,根据数据处理任务动态伸缩。
- Spark、Flink等框架实现了大规模数据的并行处理和实时流计算。
- 特征存储与管理:
- 专门的特征平台(如Feast、Tecton)负责管理特征数据的定义、存储、访问和一致性,确保训练和推理阶段使用的是相同的特征,解决“训练-服务偏斜”问题。
- 元数据与版本管理:
- 记录数据集的来源、版本、血缘关系、质量指标(元数据),以及模型、特征的版本,保证实验的可复现性和流程的可追溯性。MLflow、DVC等工具在此发挥作用。
- 数据安全与治理:
- 贯穿始终的服务,包括数据加密(静态/传输中)、访问控制、合规性检查、数据脱敏和隐私保护技术(如差分隐私、联邦学习),确保数据资产的安全合规使用。
三、
AI的数据流动并非简单的线性传输,而是一个由采集、存储、加工、消费、反馈构成的复杂闭环系统。现代AI基础设施的核心目标,就是通过整合高性能存储、弹性计算、智能数据管理以及全面的安全治理服务,将这个闭环打造得更加通畅、自动化和高效。清晰的架构图解配合坚实的底层支持服务,是释放数据价值、驱动AI持续进化的双重保障。随着AI对多模态、实时性要求的提升,存储与数据处理服务的深度集成和智能化演进,将成为新的关键赛道。
如若转载,请注明出处:http://www.xnjindouyun.com/product/42.html
更新时间:2026-06-19 10:45:13